
Chap #7February 02, 2012
프로그래밍하기: C언어-1
6장에서는 Lisp의 환경(environment)과 동적 바인딩(dynamic binding)의 특성을 활용하여 주 모드(mode)가 어떻게 구현되었는지 살펴보았다. 이번 장에서는 이맥스 안에서 (드디어!) 프로그램을 작성하고, 수정하는 기본적인 방법을 알아 보면서, 그 뒤에 숨겨진 이맥스의 내부 구조를 이해해보자.
텍스트 입력하기
우리가 같이 작성해볼 프로그램은 시저 암호화(caeser cipher) 알고리즘으로 암호화할 텍스트를 받아 암호화한 코드(cipher)를 출력한다. 이번 장에서는 컴파일형 언어인 C언어로 프로그램을 작성해보자. 먼저 C-x C-f를 입력하여 "enc.c" 파일을 생성하자.
아래의 코드를 처음부터 직접 입력해 보자! (처음 이맥스를 사용하는 분이면 꼭 해보기를 권한다.)
#include <stdio.h>
#include <string.h>
#include <err.h>
#define PRIME (17)
#define SHIFT (11)
/**
* @plain: input text
* @shift: an integer
* @prime: a prime number
*/
char* ceaser(const char *plain, int shift, int prime) {
const int len = strlen(plain);
char *cipher = (char *)malloc(len);
for (int i = 0 ; i < len ; i ++) {
*(cipher + i) = (*(plain + i) - 'a' + shift) % prime + 'a';
}
*(cipher + len) = '\0';
return cipher;
}
int main(int argc, char *argv[]) {
if (argc != 2) {
err(1, "usage: %s [text]\n", argv[0]);
}
const char *encrypted = ceaser(argv[1], SHIFT, PRIME);
const char *decrypted = ceaser(encrypted, -SHIFT, PRIME);
printf("'%s' =enc->> '%s' =dec->> '%s'\n",
argv[1], encrypted, decrypted);
return 0;
}
입력해보았다면 에디터에 비교해서 어떤 점이 불편하고, 어떤 기능들을 더 필요한가? 특히 다른 에디터에서 익숙한 기능이 있다면, 하나 하나 꼭 기록해 놓기 바란다. 앞으로 이맥스를 배워가는 과정에서, 어떻게 원하는 기능을 찾고, 찾을 수 없다면 어떻게 스스로 구현하는지 배워보도록 할 것이다.
자동 완성 (dabbrev-completion)
프로그래밍을 하면서 입력하면서 가장 먼저 절실하게? 필요한 기능은 역시 자동 완성이다. 이맥스에서 동적 자동완성 (dabbrev-completion)의 기능이 있는데, M-/: dabbrev-expand의 키입력을 통해서 호출 할 수 있다.
동적 자동완성은 앞문자들이 일치하는 단어들 중 가장 최근에 나타난 (앞선) 단어를 찾아 완성해 준다.
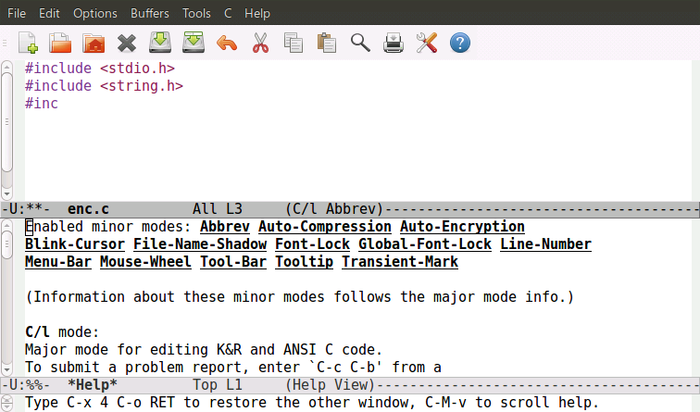
그림-1. 자동 완성
#include <stdio.h>
#include <string.h>
#inc[]
자 위의 커서에서 M-/로 자동 완성 시켜보기 바란다.
헤더 파일 열기 (find-file-at-point)
"stdio.h" 와 "string.h"의 헤더 파일은 알겠는데, "err.h"는 무슨 헤더 파일일까?
#include <stdio.h>
#include <string.h>
#include <[]err.h>
커서를 헤더 파일이름에 놓고, M-x find-file-at-point를 실행해 보자. 시스템에 "err.h" 파일의 위치를 찾아 주는가?
간단한 텍스트 수정
자주 쓰이는 텍스트 수정하는 방법들을 알아 본다.
#define rpIME (17)
#define SHIFT (11)
M-u: upper word: 단어를 대문자로 변경M-l: lower word: 단어를 소문자로 변경M-c: capitalize word: 단어의 첫 글자를 대문자로, 나머지는 소문자로C-t: transpose char: 앞/뒤 글자를 뒤바꿈M-t: transpose word: 앞/뒤 문자를 뒤바꿈C-M-t: transpose sexp: 앞/뒤 표현식을 뒤바꿈
자 잘못쓰여진 "rpIME"을 "PRIME"으로 변경하려면 아래와 같이 4번의 입력으로 할 수 있다.
C-f: 커서를 "r"에서 "p"로 옮기고C-t: "rp" -> "pr"M-b: 커서를 문자 앞으로 옮기고M-u: 대문자로 단어를 변경
사실, 두 글자 지우고 C-d 다시 "PR"을 입력하는 것 또한 4번의 입력으로 가능하다. 두 글자 지우는 것을 현재 커서에서 "p"까지 지우는 것으로 생각할 수 있다면, M-z: zap을 입력하고 "p"를 입력하면 현재 커서에서 "p"까지 지우고, 다시 "PR"을 입력할 수도 있다.
주석 쓰기
많은 언어를 접하다 보면 가장 헛갈리는 것 중에 하나가 주석 키워드 이다. 이맥스는 모든 언어들의 주석이 M-;: comment-dwim 한 키에 바인딩 되어 있다. 즉, 언어의 특징적인 주 모드들이 언어에 해당하는 주석 키워드를 이용해 주석을 생성해 준다. 또한 문맥에 따라 다른 주석을 생성하는데 아래와 같은 실험을 해보자.
[]
#define []PRIME (17)
#define SHIFT (11)
두 곳의 커서 위치에서 M-;를 입력하면 아래와 같이 하나는 현재 줄 전체에, 다른 하나는 오른쪽 공간에 주석을 생성하는 것을 볼 수 있다.
/* [] */
#define PRIME (17) /* [] */
#define SHIFT (11)
오? 그러면 주석을 지우고 싶으면? 5장에서 배운 범용 인자 C-u를 이용해서 주석을 제거해 보자. 위의 커서 위치에서 C-u M-;를 입력해서 각각의 주석을 제거하자.
또한 범위가 선택되었다면 M-;는 선택된 범위를 주석 처리 하거나, 만약에 이미 주석이 처리가 되었다면 주석을 제거할 수도 있다. 범위는 C-space: set-mark-command 를 이용해서 할 수 있고, 위의 두 define문을 선택하고 C-;를 호출해 보자.
/* #define PRIME (17) */
/* #define SHIFT (11) */
주석 문서 달기
일반적으로 C언어에서 함수/변수에 대한 문서는 "/**"로 시작하는 주석이 쓰인다.
/**
* @plain: input text
* @shift: an integer
* @prime: a prime number
*/
char* ceaser(const char *plain, int shift, int prime) {
위의 문서에서 보듯 주석의 첫줄의 ''와 두번째 줄의 ''이 잘 정돈되어 있음을 볼 수 있다. 일일이 프로그래머가 입력해 줘야 할까? 이맥스가 주석을 이해하기 때문에 주석에서의 새로운 라인은 자동으로 에디터가 정돈해 줄 수 있지 않을까? M-j: indent-new-comment-line를 입력해 보자.
/**[]
다음과 같이 커서가 변했는가?
/**
* []
스타일
많은 프로그래머들은 자기만의 코드 스타일을 가지고 있다. 필자는 모든 소스코드에 4개의 스페이스를 들여쓰기 단위로 쓴다. 하지만 기본 c-mode에서는 2개의 스페이스를 들여쓰기 단위로 사용한다.
char* ceaser(const char *plain, int shift, int prime) {[]
C-j: newline-and-indent을 함수의 선언문에서 입력해 볼까?
char* ceaser(const char *plain, int shift, int prime) {
[]
이맥스는 현재 소스 코드를 언어의 문법(Syntactic)에 따라 구조적(AST)으로 이해하고 있다. 그러면 자동 들여쓰기를 지원하는 에디터의 관점에서 소스코드를 살펴보자.
[topmost-intro=0]
char* ceaser(const char *plain, int shift, int prime) {
[defun-block-intro=+]
const int len = strlen(plain);
[statement=0]
char *cipher = (char *)malloc(len);
[statement=0]
for (int i = 0 ; i < len ; i ++) {
[statement-block-intro=+]
*(cipher + i) = (*(plain + i) - 'a' + shift) % prime + 'a';
[block-close=0]
}
[statement=0]
*(cipher + len) = '\0';
[statement=0]
return cipher;
[defun-close=0]
}
"[]" 괄호는 이맥스가 현재 (바로 밑의) 줄을 어떻게 구조적으로 이해하고 있는지 나타낸다. 그러면 +는 무엇을 의미 할까? 현재 줄의 들여쓰기에 한 단위를 더하여 다음 줄의 들여쓰기를 결정한다. 또한 0의 값은 현재 줄의 들여쓰기를 유지하고 다음줄의 들여쓰기를 한다.
자 그러면 C-h v을 통해 c-offsets-alist: 스타일 옵션들을 살펴 보자.
c-offsets-alist is a variable defined in `cc-vars.el'.
Its value is nil
Automatically becomes buffer-local when set in any fashion.
Documentation:
Association list of syntactic element symbols and indentation offsets.
As described below, each cons cell in this list has the form:
(SYNTACTIC-SYMBOL . OFFSET)
...
OFFSET can specify an offset in several different ways:
If OFFSET is nil then it's ignored.
If OFFSET is an integer ...
If OFFSET is one of the symbols `+', `-', `++', `--', ...
If OFFSET is a symbol ...
If OFFSET is a vector ...
If OFFSET is a function ...
If OFFSET is a list ...
Here is the current list of valid syntactic element symbols:
string -- Inside multi-line string.
c -- Inside a multi-line C style block comment.
defun-open -- Brace that opens a function definition.
defun-close -- Brace that closes a function definition.
defun-block-intro -- The first line in a top-level defun.
...너무 많은 (자세한) 정보에 항상 거부감이 들지만, 큰 그림으로 접근하면 매우 간단하다. "alist"인 c-offsets-alist는 이맥스가 파싱한 각각의 SYNTACTIC-SYMBOL을 얼만큼 들여쓸지 OFFSET을 통해 정의한다. OFFSET은 Lisp의 기본 타입들인 정수, 심볼, 리스트, 함수 등을 이용하여 정의할 수 있으며, 매우 직관적으로 정수면 정수 스페이스 만큼, 함수이면 함수를 호출한 후 리턴되는 값 만큼 들여쓰기를 할 것이다. 그런데 현재 줄은 어떻게 해석된 것일까?
char* ceaser(const char *plain, int shift, int prime) {
[]const int len = strlen(plain);
위의 커서에서 C-c C-o: c-set-offset을 입력해 볼까? 현재 줄은 defun-block-intro으로 해석되어 있음을 알 수있다. 그러면 4를 입력해 볼까? 그리고 C-j: newline-and-indent를 입력해 보자. 4칸이 들여 써졌는가?
스타일 변경하기
이맥스의 C언어의 기본 스타일은 GNU에서 정한 코딩 스타일을 따른다. 만약 K&R (The C Programming Language의 저자들)이나 Linux 커널의 스타일을 지키고 싶으면 어떻게 할까? 이맥스에서는 아래와 같이 잘 알려진 스타일을 정의하고 있다.
(defvar c-style-alist
'(("k&r"
(c-basic-offset . 5)
(c-comment-only-line-offset . 0)
(c-offsets-alist . ((statement-block-intro . +)
(knr-argdecl-intro . 0)
(substatement-open . 0)
(substatement-label . 0)
(label . 0)
(statement-cont . +))))
("linux"
(c-basic-offset . 8)
(c-comment-only-line-offset . 0)
(c-hanging-braces-alist . ((brace-list-open)
(brace-entry-open)
(substatement-open after)
(block-close . c-snug-do-while)
(arglist-cont-nonempty)))
(c-cleanup-list . (brace-else-brace))
(c-offsets-alist . ((statement-block-intro . +)
(knr-argdecl-intro . 0)
(substatement-open . 0)
(substatement-label . 0)
(label . 0)
(statement-cont . +))))
...)
C-c .:c-set-style을 통해 원하는 스타일을 정의해 보자. 그러면 리눅스 소스코드를 열면 "linux" 모드로 나머지 소스코드들은 "gnu"모드로? 수정하고 싶은 파일에 따라 원하는 스타일을 선택할 수는 없을까? 또 자기만의 스타일을 정의할 수는 없을까? 더 나아가서, 작성된 C프로그램은 어떻게 컴파일 하며, 어떻게 디버깅하는 것일까? 다음 장에서 나머지 C프로그램을 같이 살펴 보면서 궁금증을 하나씩 해결해 볼 것이다.